
티스토리 뷰
Solved.ac Class 완전정복 프로젝트
Class : 3 ~ 3 ++

링크
https://www.acmicpc.net/problem/2606
2606번: 바이러스
첫째 줄에는 컴퓨터의 수가 주어진다. 컴퓨터의 수는 100 이하이고 각 컴퓨터에는 1번 부터 차례대로 번호가 매겨진다. 둘째 줄에는 네트워크 상에서 직접 연결되어 있는 컴퓨터 쌍의 수가 주어
www.acmicpc.net
문제
신종 바이러스인 웜 바이러스는 네트워크를 통해 전파된다. 한 컴퓨터가 웜 바이러스에 걸리면 그 컴퓨터와 네트워크 상에서 연결되어 있는 모든 컴퓨터는 웜 바이러스에 걸리게 된다.
예를 들어 7대의 컴퓨터가 <그림 1>과 같이 네트워크 상에서 연결되어 있다고 하자. 1번 컴퓨터가 웜 바이러스에 걸리면 웜 바이러스는 2번과 5번 컴퓨터를 거쳐 3번과 6번 컴퓨터까지 전파되어 2, 3, 5, 6 네 대의 컴퓨터는 웜 바이러스에 걸리게 된다. 하지만 4번과 7번 컴퓨터는 1번 컴퓨터와 네트워크상에서 연결되어 있지 않기 때문에 영향을 받지 않는다.

어느 날 1번 컴퓨터가 웜 바이러스에 걸렸다. 컴퓨터의 수와 네트워크 상에서 서로 연결되어 있는 정보가 주어질 때, 1번 컴퓨터를 통해 웜 바이러스에 걸리게 되는 컴퓨터의 수를 출력하는 프로그램을 작성하시오.
입력
첫째 줄에는 컴퓨터의 수가 주어진다. 컴퓨터의 수는 100 이하이고 각 컴퓨터에는 11번부터 차례대로 번호가 매겨진다. 둘째 줄에는 네트워크 상에서 직접 연결되어 있는 컴퓨터 쌍의 수가 주어진다. 이어서 그 수만큼 한 줄에 한 쌍씩 네트워크 상에서 직접 연결되어 있는 컴퓨터의 번호 쌍이 주어진다.
출력
1번 컴퓨터가 웜 바이러스에 걸렸을 때, 1번 컴퓨터를 통해 웜 바이러스에 걸리게 되는 컴퓨터의 수를 첫째 줄에 출력한다.
접근방법
1번 컴퓨터로 인해 감염될 수 있는 모든 컴퓨터의 수를 구하는 문제이다. 연결되어있는 인접 노드를 모두 탐색하는 문제이며, 그래프 탐색 이론을 생각하고 풀이로 들어가자.
풀이
그래프 탐색에는 BFS(너비 우선 탐색) , DFS(깊이 우선 탐색)이 존재하는데, 해당 문제에서 본인은 DFS 알고리즘을 이용해 풀었다. 해당 문제는 연결되어 있는 인접 노드의 수를 구하는 것이므로, BFS든 DFS든 상관은 없다. DFS와 BFS를 잘 모른다면 아래 더보기를 참고하자.
DFS와 BFS 접근 방식의 차이
DFS
DFS는 리프 노드를 우선적으로 탐색하는 방식이다. 때문에 그래프의 깊이를 우선적으로 탐색하게 되어, 깊이 우선 탐색이라는 이름이 붙었다. DFS는 재귀적인 성격을 띠고 있는데, 이는 해당 노드가 갈 수 있는 곳들 중 리프 노드까지 우선적으로 방문 후, 다시 해당 노드가 갈 수 있는 다른 곳을 찾기 때문이다. 위 예제를 DFS로 탐색했을 시 방문 순서는 다음과 같다.

BFS
BFS는 현재 자신이 갈 수 있는 모든 방향을 차례로 접근한다. 때문에 리프 노드를 찾기보단 본인이 갈 수 있는 같은 깊이(Depths)의 노드를 모두 찾기 때문에 해당 이름이 붙여졌다. BFS는 자신이 갈 수 있는 모든 인접 노드를 확인하면서 리프 노드까지 가기 때문에, 순차적이며 큐 구조의 성격을 가지고 있다. 위 예제를 BFS로 탐색했을 시 방문 순서는 다음과 같다.
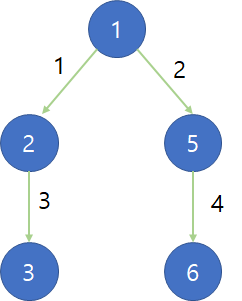
방문한 노드만큼 더한 후, 1번 컴퓨터는 이미 감염된 상태 이므로 하나의 노드만 빼주면 된다.
코드
DFS
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
Main test = new Main();
}
public Main() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer stk ;
int node =Integer.parseInt(br.readLine());
boolean[][] arr = new boolean[node][node];
boolean[] visit = new boolean[arr.length];
int cnt = Integer.parseInt(br.readLine());
for (int i = 0 ; i < cnt ;i++){
stk = new StringTokenizer(br.readLine()," ");
int a = Integer.parseInt(stk.nextToken())-1;
int b = Integer.parseInt(stk.nextToken())-1;
arr[a][b] = true;
arr[b][a] = true;
}
int result = solution(arr,visit,0);
System.out.println(result-1);
}
private int solution(boolean[][] arr, boolean[] visit, int start) {
int result =1;
visit[start] = true;
for (int i = 0 ; i < arr.length ; i++){
if (arr[start][i] && !visit[i]){
result+= solution(arr, visit, i);
}
}
return result;
}
}
BFS
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
Main test = new Main();
}
public Main() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer stk ;
int node =Integer.parseInt(br.readLine());
boolean[][] arr = new boolean[node][node];
boolean[] visit = new boolean[arr.length];
int cnt = Integer.parseInt(br.readLine());
for (int i = 0 ; i < cnt ;i++){
stk = new StringTokenizer(br.readLine()," ");
int a = Integer.parseInt(stk.nextToken())-1;
int b = Integer.parseInt(stk.nextToken())-1;
arr[a][b] = true;
arr[b][a] = true;
}
int result = solution(arr,visit,0);
System.out.println(result-1);
}
private int solution(boolean[][] arr, boolean[] visit, int start) {
//들어올때마다 1
int result =0;
Queue<Integer> que = new LinkedList<>();
que.add(start);
while (!que.isEmpty()){
int cur_loc = que.poll();
//방문한 곳은 넘긴다.
if (visit[cur_loc]){
continue;
}
visit[cur_loc] = true;
result++;
for (int i = 0 ; i < arr.length ; i++){
if (arr[cur_loc][i] && !visit[i]){
que.add(i);
}
}
}
return result;
}
}
결과

생각보다 시간이 오래걸렸다. 꼼꼼하지 못한 것이 가장 큰 원인이 아닐까 싶다.
인접 노드의 관계를 정의할 때 visit [a][b]는 하고 visit [b][a]는 안 한 그런 것들, 쓸데없는 코드들로 시간 손해를 꽤나 본 기분이다. 전날보다 생각에 기반한 코딩은 잘되었지만, 기본에 더 충실하게 접근하자.
포스팅에 문제가 있거나, 설명이 잘못된 부분 지적 환영합니다.
더 나은 퀄리티의 콘텐츠를 제공할 수 있도록 노력하겠습니다.
읽어주셔서 감사합니다.
'공부 > 코딩 테스트 준비' 카테고리의 다른 글
| [백준] 16928 - 뱀과 사다리 게임 JAVA (0) | 2021.09.28 |
|---|---|
| [백준] 1697 - 숨바꼭질 (0) | 2021.09.28 |
| [백준] 1992 - 쿼드 트리 JAVA (0) | 2021.09.25 |
| [백준] 1927 - 최소 힙 JAVA (0) | 2021.09.24 |
| [백준] 17626 - Four Squares JAVA (0) | 2021.09.23 |
- Total
- Today
- Yesterday
- dml
- 파이썬
- Python
- 브루트포스
- 실패일기
- java
- 플루이드 와샬
- 하루 회고
- DP
- DFS
- 코딩테스트
- 프로그래머스
- 자바
- 그래프 탐색
- value annotation
- JNDI연동
- 프로그래머스 문제정복
- db
- looker instance 접속
- 9019
- 아기상어나쁜상어
- Database
- 재귀
- 백준
- BFS
- 아기상어미워
- 유클리드-호제법
- Spring
- 카카오
- looker core
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |